[SQL] SQL문 실행 원리
1. Parsing 파싱
- SQL문에는 처리 방법이 적혀 있지 않기 때문에 처리 방법을 생성할 필요가 있음
- 처리 방법을 공유 풀에 캐시 해두고 재활용 하기 위함
- SQL문 처리 횟수와 처리 시간을 줄여 성능을 향상 시키기 위함
- 오라클은 해시 알고리즘을 사용해 SQL문 마다 ID를 생성
- SQL 문을 문자열로 해시 함수에 입력하고 출력된 해시 값을 SQL문의 ID로 사용
- 문자열로 입력 받기 때문에 대문자와 소문자를 구별하여 해시 값이 달라짐
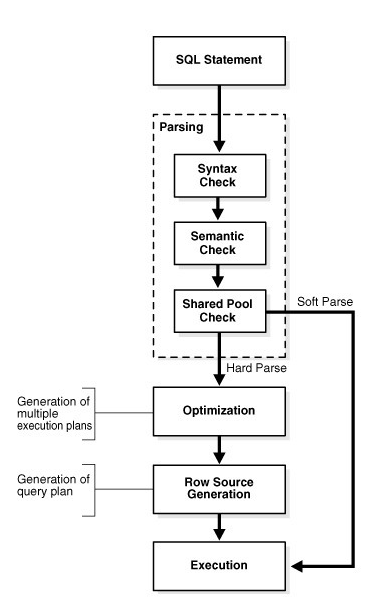
1. Syntax Check (문법 검사)
: 키워드(SELECT, FROM, WHERE..) 검사
2. Semantic Check (의미 검사)
: 테이블, 컬럼등의 사용자마다 다른 부분 검사
-> 다른 부분이 없다면 오류
3. Shared Pool Check (lib. 캐시 확인)
: SQL 또는 PL/SQL 문장 결과가 Lib. cache* 내에 있는지 조회
-> 있으면 Soft Parse → Execution, 없으면 Hard Parse → Optimization
3.1 Optimization (≒ 네비)
: Data Dictionary 등을 참조해서 실행계획 생성
3.2 Row Source Generation
: 3.1 단계에서 가장 좋은 계획 선택
4. Execution (수행)
+ Optimizer
= Parser(파서) / SQL문을 분석하고 최적의 '실행계획' 을 생성하는 기능
조인에서 어느 테이블을 먼저 읽어야 하는지, 어떤 인덱스를 실행시켜야 좋은지 등을 판별 (척도 RBO(Rule Base Optimizer) / CBO(Cost Based Optimizer*)
*RBO - Server Process가 실행 계획을 세워달라고 요청이 오면 미리 정해놓은 규칙 사용
CBO - Data Dictionary 내용 참고하여 판별 / 10g 하위 버전은 Data Dictionary 자동으로 업데이트 X
| * Library Cache - 해시구조로 관리 - SQL 쿼리마다 해시값을 매핑해서 저장 |
2. 처리 단계

- Parse(구문 분석) : 실행계획을 세우고 가장 좋은 실행계획을 선택하기 위한 과정
- Bind(값 치환) : 같은 쿼리문을 줄이는 과정
Hard Parse를 줄여주어서 성능 향상에 도움
cf) PGA에서 Bind 변수 저장 하는 곳 = Persistent Area
- Execute(실행) : Data File에서 원하는 데이터를 Buffer Cache로 복사해오는 과정 (∵ Server Process가 데이터 조회 가능)
- Fetch(인출) : Block 단위로 복사된 데이터에서 원하는 데이터만 뽑아 가는 과정
+ DML - UPDATE (SELECT 제외한 DML)
Parse -> Bind → Redo Log Buffer에 기록 → Undo Segment에 기록 → DB Buffer Cache의 실제 데이터 변경
1. Execute 과정에서 서버프로세스는 데이터의 변경 내역을 Redo Log Buff.에 기록
2. Undo Segment에 이전 데이터 기록
3. Data Buffer Cache의 내용 변경